亚马逊的 Alexa 科学家展示了更大的人工智能并不总是更好的
亚马逊的 Alexa 科学家展示更大的人工智能并不总是更好的
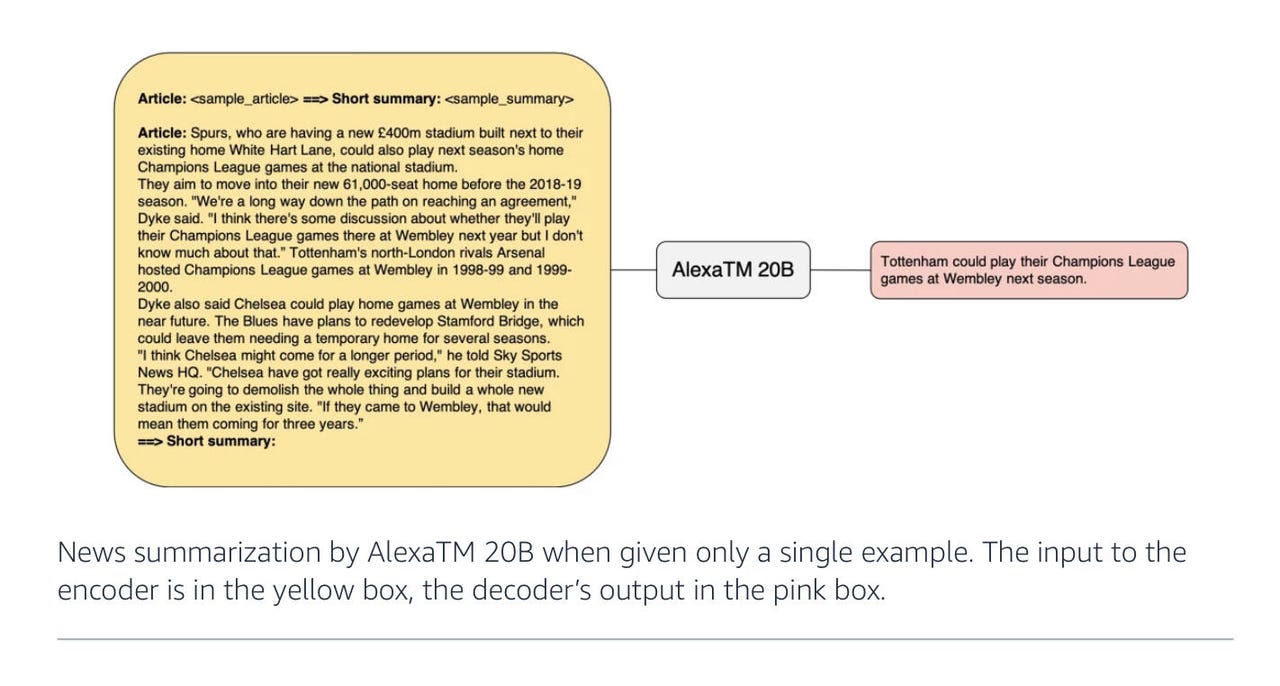
一个简单的任务,将一篇文章中的所有文字减少到一串简洁的文字,解释文章的核心观点,是深度学习中的基准任务之一。这就是亚马逊的Alexa AI科学家们声称他们可以胜过来自DeepMind、谷歌、Meta、OpenAI和其他公司的规模大得多的计算机程序的努力的地方。这项工作对能源使用和碳足迹效率有着重要的影响。
当今机器学习领域有两个主要的研究方向:使程序在处理任何潜在任务时更具一般性,以及使它们更大。
以参数或“权重”来衡量,最大的神经网络的权重已经超过了半万亿。谷歌的Pathways语言模型(PaLM)和Nvidia和微软的Megatron-Turing NLG 530B等模型是最大的模型之一,分别具有5400亿和5300亿个参数。一般来说,一个程序拥有的参数越多,它在训练时所消耗的计算能力就越大,而在进行预测时所需要的计算能力也越大,这被称为推理。
人工智能
- 7个高级ChatGPT提示写作技巧,你需要了解
- 2023年最佳的10个ChatGPT插件(以及如何充分利用它们)
- 我已经测试了很多工作中的智能工具。这是我迄今为止最喜欢的5个
- 人还是机器人?这个图灵测试游戏让你的AI辨别技能接受考验
人工智能的专家坚持认为,在参数数量方面,路径肯定是向上和向右的,朝着万亿级别的参数以及未来更高的目标发展。100万亿这个数字被认为是人脑中的突触数量,因此它作为一个基准。
另外: Nvidia澄清了Megatron-Turing的规模声明
与此同时,人们热衷于制造能够尽可能一般化的深度神经网络。在过去的40年中,机器学习的程序大多专门用于图像识别或语音识别等任务。近年来,情况发生了变化,越来越多的程序提供了通用性,比如DeepMind的Perceiver AR和另一个DeepMind的程序Gato,被称为“通用代理”,能够解决各种任务。
这种一般化的倾向得到了机器学习先驱Richard Sutton等人的观察的支持,他们指出“从历史上看,更好地利用计算能力的通用模型也往往最终超过了更专门的领域特定方法。”
另外: DeepMind的’Gato’不起眼,为什么还要建造它?
然而,有时也会出现深度学习结果与巨大和通用相反,而是经济和稍微专注的情况。
与那些大规模努力相比,亚马逊的研究人员上周发布了一个只有200亿参数的神经网络程序,在某些重要的深度学习基准任务上胜过了一些最大、最通用的模型,比如如何概括一篇文章。
在上周发布的论文“AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model”中,作者Saleh Soltan和亚马逊Alexa AI的同事展示了200亿参数足以在某些任务上击败像PaLM这样的更大模型,比如用几句话概括一篇文章。
除了论文,Soltan还写了一篇关于这个主题的博文。
亚马逊的工作是最近文献中寻找增加模型规模以外的替代方案的广泛趋势的一部分。Meta(Facebook和Instagram的所有者)上周发布的一篇名为“Few-shot Learning with Retrieval Augmented Language Models”的论文就是一个很好的例子。它描述了一个名为Atlas的语言模型,只有110亿个参数,并且仅使用了64个示例数据点进行训练。
正如作者所写的那样,在仅有64个示例的情况下,Atlas程序大大超过了PaLM。Atlas的关键在于将预训练语言模型与从在线源(如维基百科)检索信息的能力相结合,就像给朋友打电话获取答案一样。
此外:DeepMind的Perceiver AR:迈向更高效的人工智能
在AlexaTM 20B的情况下,亚马逊的作者使用了三个调整来实现他们的得分。
亚马逊 2022 AlexTM 20B 图表
第一个有趣的调整是回归基础,并恢复最近的大型语言模型中删除的某些内容。AlexaTM 20B的基础与PaLM、GPT-3和其他模型相同,即Transformer编码器-解码器——这种方法由Google科学家Ashish Vaswani和他的同事于2017年首创。
Transformer使用称为“自注意力”的单元,为每个单词在上下文中的出现概率得分。然后,当预测单词以形成有意义的文本块时,使用该得分填充空白。
在AlexaTM 20B的情况下,Soltan和他的同事与PaLM、GPT-3和其他原始Transformer的巨大后代有了重大分歧。这些较新的模型放弃了Transformer的一半,即被称为编码器的部分(将输入数据映射为隐藏状态,然后解码为答案)。相反,PaLM和GPT-3将输入与解码器合并,形成了一个精简的“仅解码器”模型。
亚马逊团队将编码器重新引入程序。他们声称同时拥有这两个元素有助于提高“去噪”任务中的准确性,即在一些单词丢失的情况下重构原始句子。
在仅解码器模型中,预测文本的条件概率仅沿一个方向运行:每个下一个答案仅基于之前的内容。相比之下,完整的编码器-解码器版本在两个方向上对概率进行评估:给定单词之前和之后的内容。这在不仅生成句子中的下一个元素,还进行诸如逐字比较的任务(例如从一种语言到另一种语言的翻译)中更有效。
亚马逊 2022 AlexTM 20B 仅解码器模型
此外:Meta在希腊语、亚美尼亚语和奥罗莫语上仍然存在问题
正如他们所写的,“AlexaTM 20B在去噪模式的零样本设置中实现了82.63%的新最高水平。去噪模式之所以在这个任务中表现更好,主要原因是在去噪模式中,输入在编码器和解码器中被重复使用,使得模型可以完全利用编码器和解码器来找到最佳答案。”
作者添加的第二件事是使用所谓的“因果语言建模”训练模型。简称CLM,这是GPT-3和其他仅解码器Transformer中使用的任务。它特别将每个单词表示为仅依赖于之前出现的单词,即基于初始提示训练生成句子的顺序单向依赖。
作者将去噪任务与因果任务混合训练AlexaTM 20B,其中去噪任务占训练活动的80%,因果建模占剩下的五分之一。
添加因果建模的好处是,类似于GPT-3,它有助于所谓的“上下文学习”。上下文学习是一个广泛的概念,涵盖了能够进行零样本或少样本学习的任何模型。这意味着程序没有领域特定的知识;只需给它一个示例提示,程序就会根据提出的问题类型进行预测。
由于这种混合训练模式,AlexTM 20B不仅在重构句子(去噪任务)方面表现出色,而且是“第一个能够进行上下文学习的多语言seq2seq [序列到序列]模型”,作者写道。换句话说,它是一个混合程序。
Soltan和他的同事的第三个有趣的调整是在训练过程中大幅增加输入到程序的数据点数量。在训练过程中,他们输入了一万亿个“令牌”,即个别的数据片段,这比GPT-3收到的数量多三倍以上。在这种情况下,训练数据集包括维基百科条目和被称为mC4的数据集,这是去年由Google的Linting Xue和他的同事介绍的用于训练Transformer的数据集。它基于Common Crawl网络抓取的101种语言的自然语言文本数据源。
此外:有感知能力?Google LaMDA感觉像一个典型的聊天机器人
使用大量的输入训练数据是Alexa工作的关键要素之一。索尔坦和团队决定选择这条路线,他们写道,这是基于Jordan Hoffman和OpenAI同事在今年三月发表的一篇论文中的观察结果,该论文名为“训练计算最优的大型语言模型”。
在那篇论文中,Hoffman和同事得出结论:“目前的大型语言模型训练不足,这是近期关注缩放语言模型而保持训练数据量恒定的结果。”作者们采用了不同规模的语言模型,并以不同数量的输入标记测试了所有这些模型,他们得出的结论是:“对于计算最优的训练,模型大小和训练标记数量应等比例缩放。”
因此,AlexaTM 20B不仅仅是简约的 – 它旨在证明更少的参数可以与更多的训练数据平衡,以达到引人注目的性能。
ENBLE推荐
选择哪种亚马逊Echo设备?如何选择最适合您需求的Alexa设备
亚马逊现在有一整套的Echo设备。有些可以听到您的声音。有些还可以观察您。您应该选择哪一个呢?我们将帮助您做出决策。
顺便说一下,作者们还努力确保大部分输入都是自然口语文本,省略了大写和标点符号,这在Alexa环境中很重要。他们写道:“我们包含更多的口语文本来满足我们的内部用例。”
亚马逊告诉ENBLE在一封电子邮件中,Alexa AI团队的一些技术也用于Alexa产品,但他们同时也进行前瞻性研究。亚马逊表示,AlexaTM 20B模型目前主要是一个研究项目。
亚马逊补充说:“这个模型有可能在未来被部署到生产环境中,但只有带有保护措施的修改版本将用于开发Alexa功能和产品。”
此外:Google的大规模语言翻译工作揭示了其失误
作者们在128块[Nvidia] A100 GPU上对AlexaTM 20B模型进行了120天的训练,共进行了500,000次更新,累积批处理大小为2百万个标记(总共进行了1万亿个标记的更新)。
这听起来可能很多,但它比Google在两个第四代TPU Pod上训练的PaLM要少,每个Pod由3072块TPU芯片组成,连接到768台主机计算机上。
正如Google作者Aakanksha Chowdhery和团队在今年四月指出的,这是“迄今为止最大的TPU配置”。
具体的测试结果已经列出。索尔坦和团队特别强调了他们在特定任务上的成功,而不是每个任务都考虑到。例如,索尔坦和团队观察到,“AlexaTM 20B在摘要任务中表现得比迄今为止最大的仅解码模型(即PaLM 540B)更好或者差不多”,这在一项名为MLSum的总结段落任务中尤其明显;在德语、西班牙语和法语方面,AlexaTM 20B轻松击败了PaLM。
MLSum基准测试是由法国国家科学研究中心于2020年引入的,包括150万篇报纸文章。任务是让语言模型输出几句表达整篇文章中所阐述的思想的文本。这需要对数百个单词进行大量的概括,从而缩减到几十个。
亚马逊
- 如何将旧Fire平板变成Echo Show
- 用您的旧设备换取亚马逊礼品卡。这里是如何操作的
- 最好的亚马逊平板电脑:玩火
- 亚马逊Kindle Scribe评论:七个月后,它接近完美
在第四项英语测试XSum中,AlexaTM 20B模型仅次于第一名,击败了比AlexaTM 20B更大但比5400亿参数版本的PaLM。
尽管在摘要任务上表现出色,但AlexTM 20B在其他一些任务上表现不佳。例如,在“推理”数据集(如MultiArith)和“思维链”推理任务(这些是用自然语言编写的非常简单的算术问题)上进行测试时,该程序远远落后于像GPT-3这样规模更大的模型所能达到的成就。
还有:Graphcore首席执行官表示,人工智能的未来是一个软件故事
索尔坦和团队写道:“AlexaTM 20B的性能略优于类似规模的模型,但我们并没有观察到像GPT3 175B这样更大模型从特殊提示中获得的收益”,这意味着给程序关于问题下一步的线索。
“结果表明,扩大模型参数在执行‘推理’任务中至关重要,这之前在使用Instruct-GPT3模型的纯解码器架构中已经得到了证明。”
索尔坦和团队主要关注成功的任务,比如摘要,他们得出的主要结论是,他们混合训练该程序的方法——同时使用去噪和因果语言建模的目标——是提高效率的关键。
“这表明,混合预训练,而不一定是额外的多任务训练,是训练强大的基于seq2seq的大规模语言模型(LLM)的关键。”他们写道。
回到最初的大小问题,正如在许多情况下所指出的,越来越大的人工智能程序的能源使用是人工智能实践中的伦理关注。作者们提出了关于他们更高效方法的相关性的有力论据。
还有:人工智能的伦理:人工智能的益处与风险
他们写道,因为AlexaTM 20B“在规模上比GPT3 175B等模型要小得多,但在不同任务上实现了类似或更好的性能”,“使用AlexaTM 20B进行推理的持续环境影响要比更大模型低得多(大约低8.7倍)。”
他们补充道:“因此,随着时间的推移,AlexaTM 20B的碳足迹也更低。”
作者们提供了一张统计数据表,显示了相对碳足迹的差异。
这是一个亚马逊2022年AlexTM 20B碳足迹比较图表。
这张碳足迹表可能是最有趣的方面。似乎更多的深度学习研究将寻求提供环境评估的分数,以展示给定方法的能源效率。这与世界对“ESG”(环境、社会和治理因素)的关注不断增加是一致的。
这可能意味着环保意识在某种程度上已经成为主流人工智能研究的目标的一部分。
还有:60秒内的人工智能






